Abstract
Most existing 3D referring expression segmentation (3DRES) methods rely on dense, high-quality point clouds, while real-world agents such as robots and mobile phones operate with only a few sparse RGB views and strict latency constraints. We introduce Multi-view 3D Referring Expression Segmentation (MV-3DRES), where the model must recover scene structure and segment the referred object directly from sparse multi-view images. Traditional two-stage pipelines, which first reconstruct a point cloud and then perform segmentation, often yield low-quality geometry, produce coarse or degraded target regions, and run slowly. We propose the Multimodal Visual Geometry Grounded Transformer (MVGGT), an efficient end-to-end framework that integrates language information into sparse-view geometric reasoning through a dual-branch design. Training in this setting exposes a critical optimization barrier, termed Foreground Gradient Dilution (FGD), where sparse 3D signals lead to weak supervision. To resolve this, we introduce Per-view No-target Suppression Optimization (PVSO), which provides stronger and more balanced gradients across views, enabling stable and efficient learning. To support consistent evaluation, we build MVRefer, a benchmark that defines standardized settings and metrics for MV-3DRES. Experiments show that MVGGT establishes the first strong baseline and achieves both high accuracy and fast inference, outperforming existing alternatives.
Task & Benchmark
The MV-3DRES Task
Real-world agents (robots, mobile phones) often operate with sparse RGB views and strict latency constraints, unlike traditional methods that rely on pre-built dense point clouds.
We introduce Multi-view 3D Referring Expression Segmentation (MV-3DRES). The goal is to segment a 3D object described by natural language directly from a few sparse images, without any ground-truth 3D input at inference.
Challenges:
- Incomplete Geometry: Sparse views lead to noisy and partial 3D reconstruction.
- Weak Supervision: The target object occupies a tiny fraction of the 3D space, leading to optimization difficulties.
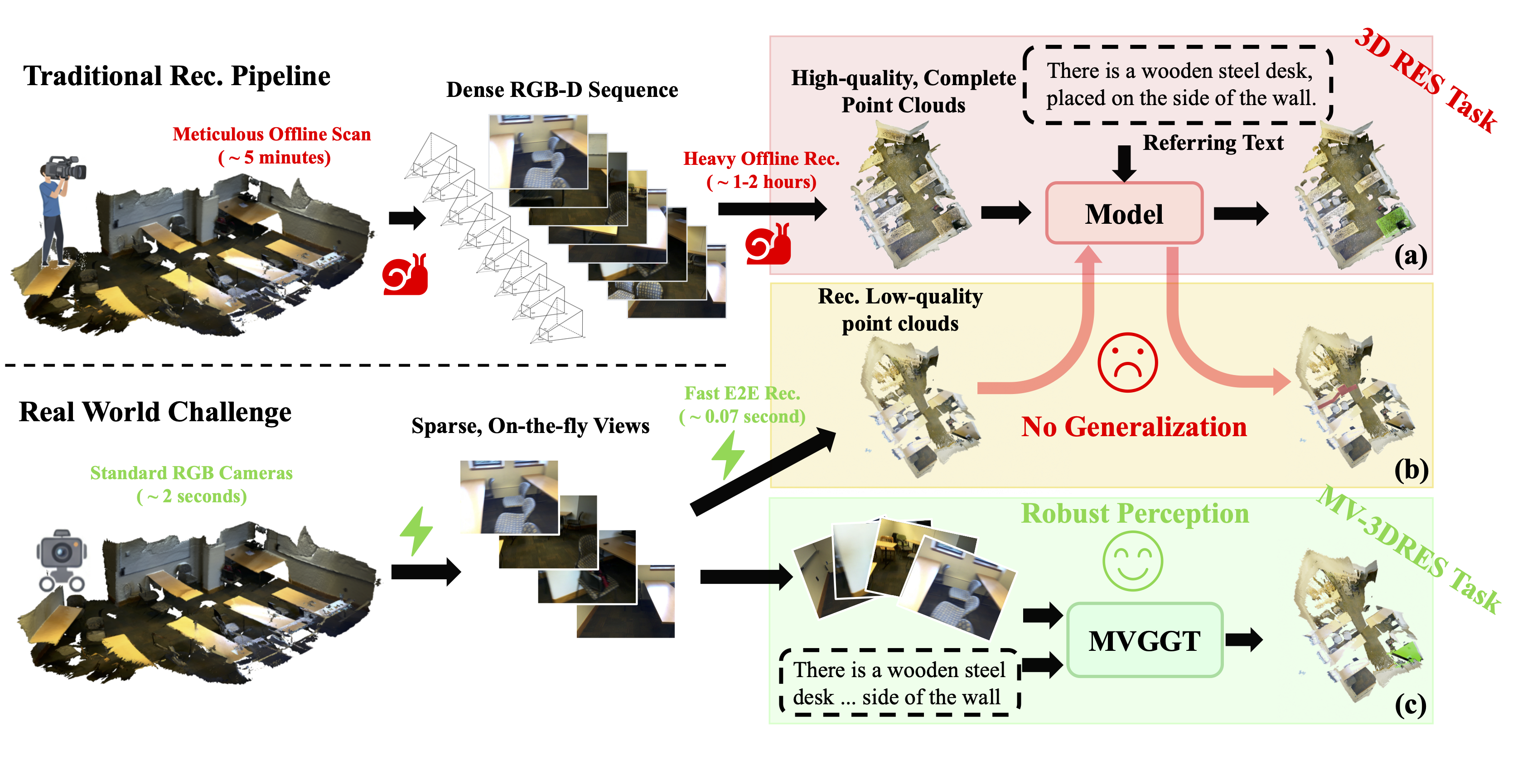
Figure 1: Comparison of the proposed MV-3DRES task (bottom) against the traditional two-stage reconstruction-then-segmentation pipeline (top) and direct reconstruction failures (middle).
MVRefer Benchmark
To standardize evaluation, we built MVRefer based on ScanNet and ScanRefer. It emulates embodied agents by sampling N=8 sparse frames. We provide metrics that decouple grounding accuracy from reconstruction quality, including mIoUglobal (3D) and mIoUview (2D projection).
Method: MVGGT
We propose the Multimodal Visual Geometry Grounded Transformer (MVGGT), an end-to-end framework designed for efficiency and robustness.
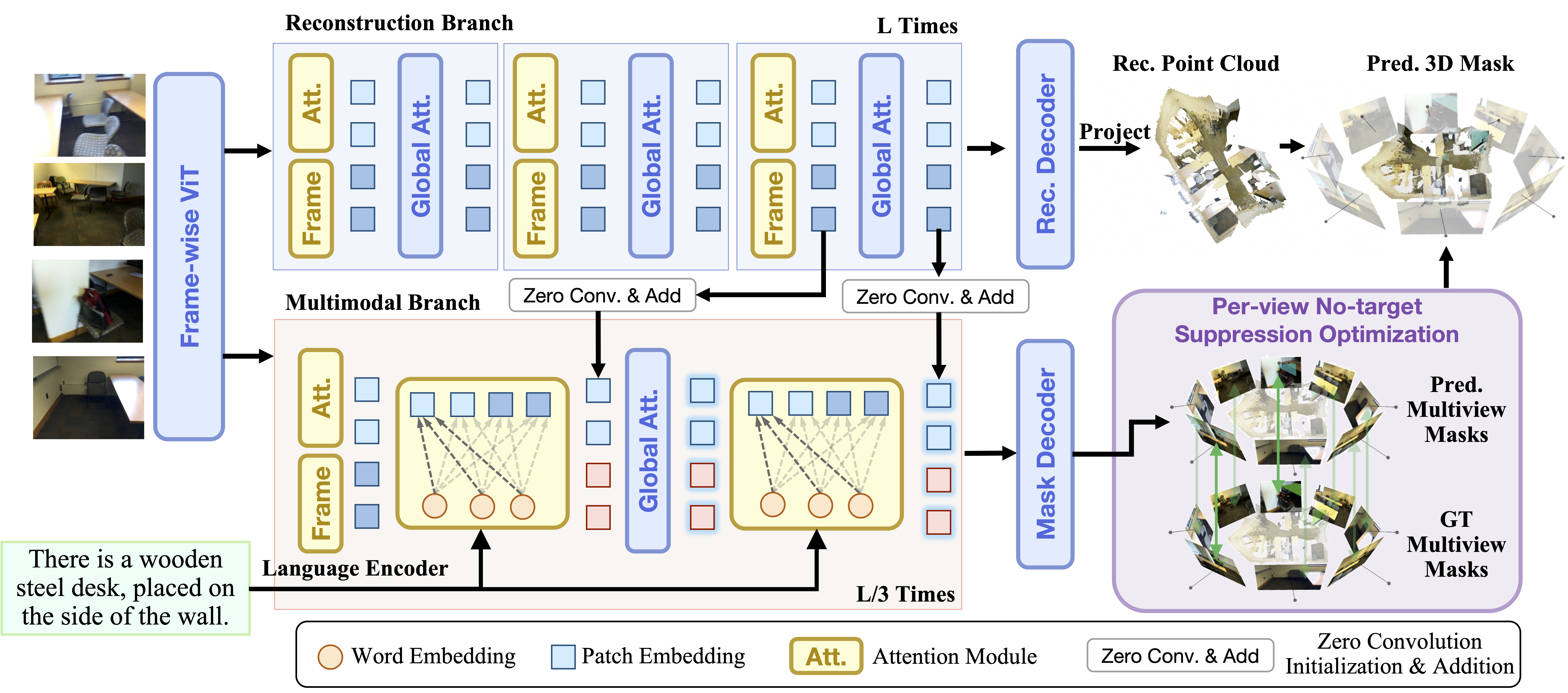
Figure 2: Architecture of MVGGT. It features a Frozen Reconstruction Branch (top) that provides a stable geometric scaffold, and a Trainable Multimodal Branch (bottom) that progressively injects language cues into visual features to predict the final 3D segmentation.
Dual-Branch Architecture
- Frozen Reconstruction Branch: Uses a pre-trained geometry transformer to predict camera poses and depth maps, providing a stable geometric scaffold.
- Trainable Multimodal Branch: Injects language features into visual representations. It receives geometric guidance from the frozen branch to align semantics with structure.
Solving the "Needle in a Haystack" Problem
The Problem (FGD): In sparse 3D space, the target object is extremely sparse (< 2%), causing the background to dominate the gradients. We call this Foreground Gradient Dilution.
Our Solution (PVSO): We introduce Per-view No-Target Suppression Optimization. Instead of relying solely on weak 3D signals, we enforce supervision in the dense 2D image domain.
- Concentrated Signal: Foreground takes up ~15% of pixels in 2D views vs < 2% in 3D.
- Balanced Training: We dynamically sample target-visible views to ensure strong gradients.
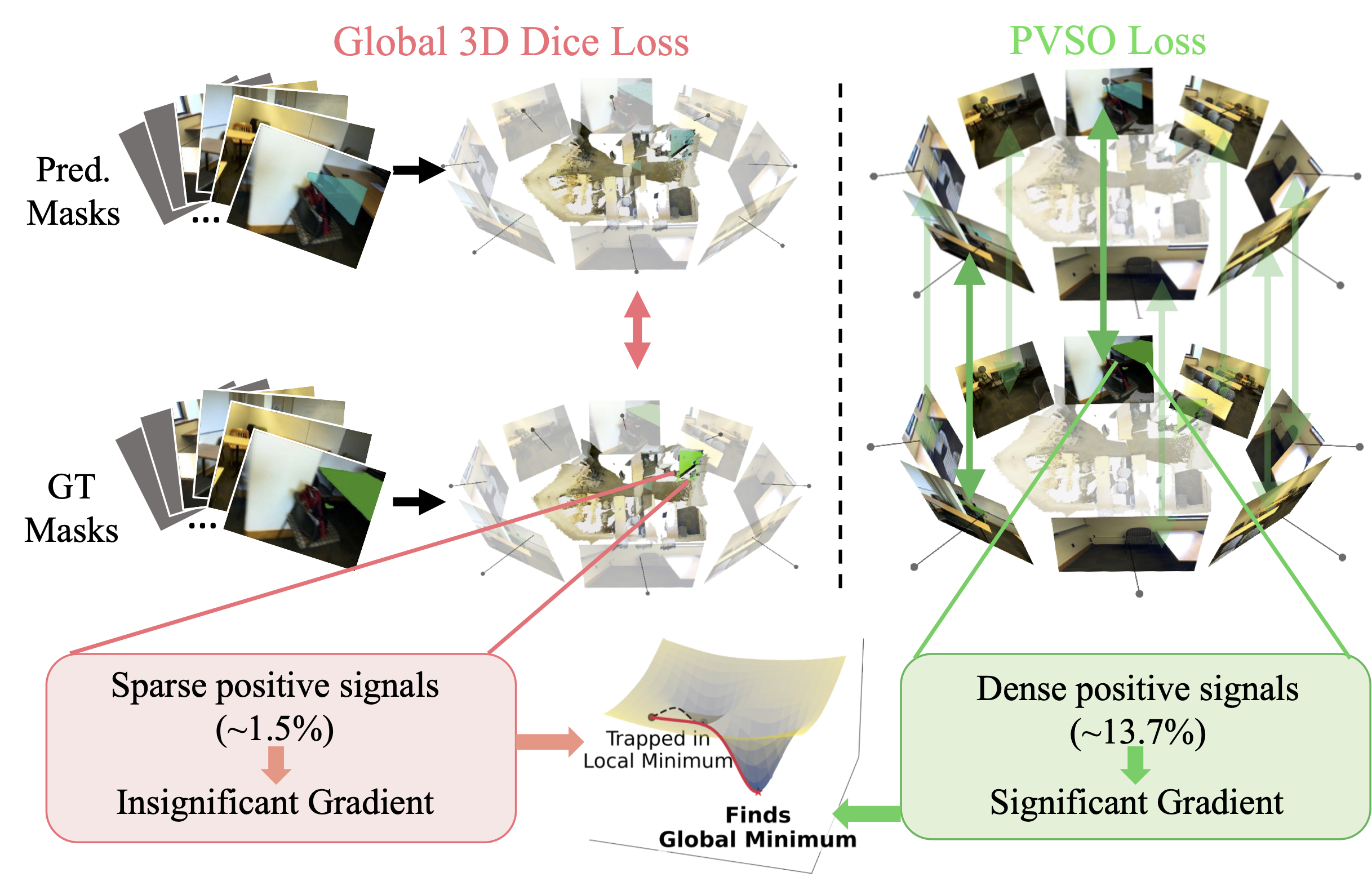
Figure 3: Visualizing the optimization challenge and our solution.
Qualitative Visualization
Reconstruction and Segmentation of ScanNet Photos/Videos with MVGGT. Click on any thumbnail below to view the 3D reconstruction.
the cabinet is in the northwest corner of the room. the cabinet is a white rectangular box.
Qualitative Comparison
MVGGT significantly outperforms all other methods. Please refer to our paper for quantitative results. Here we also provide a qualitative comparison with 2D-Lift and Two-Stage methods (use the dropdown menu to switch).
the fridge is tall, rectangular, and white. it is located to the right of the stove.
In-the-wild Visualization
Reconstruction of In-the-wild Photos/Videos with MVGGT.
It is a 3-seater sofa. Its upholstery is light beige. It has seat and back cushions, and black metal legs.